Image-to-Image Translation with Conditional Adversarial Networks
Abstract
우리는 conditional adversarial networks(조건적 적대 신경망)을 이미지-이미지 변환 문제에 대한 범용 해결방안으로 연구했다. 이 신경망은 단순히 입력 이미지에서 출력 이미지로의 매핑뿐만이 아니라, 이 매핑을 훈련시키기 위한 손실 함수 또한 학습한다. 이는 전통적으로 매우 다양한 손실 공식을 필요로 하는 문제들에 대한 똑같은 일반적인 접근을 가능케 한다. 우리는 이러한 접근이 레이블된 지도에서 사진을 합성하고, edge map에서 객체를 재구성하고, 이미지를 채색하는 등의 작업에서 효과적임을 설명한다. 물론 이 논문과 관련한 pix2pix 소프트웨어의 공개 이후 예술가를 포함한 다수의 인터넷 사용자가 우리의 시스템을 이용하여 그들의 실험 결과를 보여주었고, 이는 더 나아가 매개변수의 조절의 필요 없이 넓은 적용 가능성과 채택의 용이성을 보여준다. 더 이상 매핑 함수에 대한 수작업을 통한 설계가 필요 없으며, 이는 또한 우리가 손실 함수에 대한 수작업이 없이도 합리적인 결과에 도달할 수 있음을 제시한다.
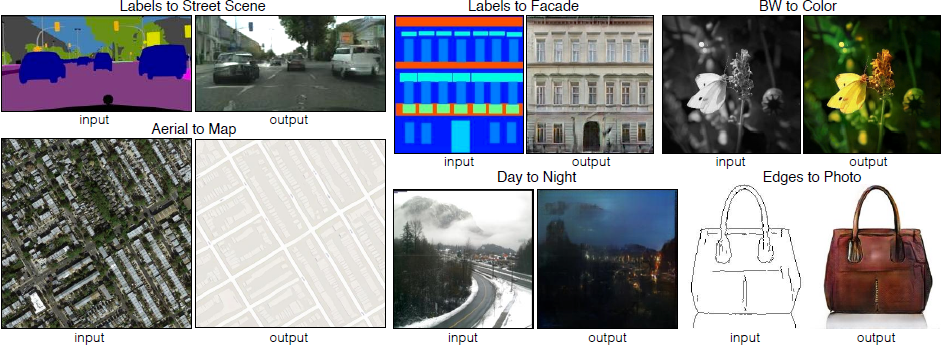
Figure 1: 입력 이미지를 관련된 출력 이미지로 변환하는 이미지 처리, 그래픽, 비전에서의 다양한 문제들. 이 문제들은 항상 픽셀을 픽셀로 매핑하는 똑같은 설정임에도 자주 특정 용도에 맞추는 알고리즘으로서 다루어진다. Conditional adversarial net(조건적 적대 신경망)은 이러한 넓은 다양성을 지닌 문제들에 잘 적응하는 것으로 보이는 범용 해결 방안이다. 이 논문에서는 여러 방법으로 이 방법론의 결과를 보여준다. 각각의 경우에 대해 같은 아키텍쳐와 목적 함수를 사용하고 간단히 다른 데이터에 대해서 학습한다.
1. Introduction
이미지 처리, 컴퓨터 그래픽스, 그리고 컴퓨터 비전의 많은 문제는 입력 이미지를 그에 관련한 출력 이미지로 “변환하는” 문제로 볼 수 있다. 어떠한 개념이 영어 또는 프랑스어로 표현될 수 있듯이, 어떠한 장면도 RGB 이미지, 그레이디언트 필드, 엣지 맵, 시멘틱 레이블 맵 등으로 표현될 수 있다. 자동 언어 변환에 대한 유추로, 우리는 자동 이미지-이미지 변환을 (충분한 훈련 데이터를 사용하여) 장면에 대한 가능한 표현을 다른 표현으로 변환하는 작업으로 정의한다. 전통적으로, 이러한 각각의 작업은 픽셀에서 픽셀을 예측하는 항상 똑같은 설정을 가짐에도 분리된, 특수 목적의 기계(machinery)로서 다루어졌다. 이 논문의 목표는 이러한 모든 문제에 대하여 공통된 프레임워크를 개발하는데에 있다.
연구 커뮤니티에서는 이러한 방향에서 상당한 양의 연구를 진행해왔고, 다양한 이미지 예측 문제에서 합성곱 신경망(Convolutional Neural Network, CNN)이 공통적인 역할을 해내고 있다. CNN은 손실 함수(결과의 품질을 점수로 매기는 목적 함수)를 최소화 하도록 학습하며, 학습 과정이 자동으로 진행되더라도 효율적인 손실을 설계하기 위해 다량의 수작업을 필요로 한다. 다시 말하자면, 우리는 여전히 CNN에게 어떤 것을 최소화하고 싶은지를 알려주어야 한다. 이에 대해 naive한 접근을 취하고 CNN이 예측 값과 실제 값 사이 유클리디안 거리를 최소화하도록 한다면 흐린 결과물을 만들어내는 경향을 보인다. 이는 유클리디안 거리가 모든 가능한 출력을 평균하며 최소화되기 때문이다. 선명하고 사실적인 이미지를 출력하는 것과 같이 CNN이 우리가 원하는 것을 행하도록 하는 손실 함수를 찾아내는 것은 열려있는 문제이며 일반적으로 전문적인 지식을 필요로 한다.
이러한 방법 대신에 “출력을 현실과 구분하기 어렵게 만드는 것”과 같은 고수준의 목표를 특정한 다음, 이 목표를 충족시키기에 적절한 손실 함수를 자동적으로 학습하는 것은 상당히 바람직할 것이다. 운이 좋게도, 이는 최근에 나온 생성적 적대 신경망(Generative Adversarial Network, GAN)이 하는 것과 정확히 일치한다. GAN은 출력 이미지가 실제인지와 거짓인지를 구분하기 위한 손실 함수를 학습하면서 동시에 이 손실을 최소화하려는 생성 모델을 학습한다. 흐린 이미지들은 명백히 거짓 이미지로 보이므로 이 신경망에서 용인되지 않는다. GAN이 데이터에 적응하는 손실을 학습하므로, 매우 다양한 종류의 손실 함수를 필요로 하는 이전의 다수의 작업에 적용될 수 있다.
이 논문에서, 우리는 특정 조건의 GAN을 탐구한다. GAN이 데이터에 대한 생성 모델을 학습하는 것처럼, conditional GAN(cGAN)은 조건부 생성 모델을 학습한다. 이는 cGAN이 입력 이미지로 조건을 설정하고 그에 대한 출력 이미지를 생성하는 이미지-이미지 변환 작업에 적합하도록 만든다.
GAN은 지난 2년 동안 활발하게 연구되었고, 이 논문에서 연구하는 많은 기술들은 이전에 제안되었던 것들이다. 하지만 앞선 논문들은 특정한 응용에만 초점을 맞추었으며, image-conditional GAN이 이미지-이미지 변환에 대해 얼마나 효과적인 범용 해결책이 될 수 있는지는 명확하지 않은 채로 남아있다. 우리의 첫 번째 기여는 넓은 범위의 문제에 대해 conditional GAN이 합리적인 결과를 만들어냄을 입증하는 것이다. 두 번째는 좋은 결과에 도달하기에 충분한 간단한 프레임워크를 보이고, 몇 가지 중요한 구조적 선택의 효과를 분석하는 것이다. 코드는 다음 링크에서 확인할 수 있다.
2. Related work
Structured losses for image modeling
이미지-이미지 변환 문제는 주로 픽셀마다의 분류 또는 회귀로 공식화된다. 이러한 공식화는 주어진 입력 이미지에서 각각의 출력 픽셀이 모든 다른 픽셀들과 조건부 독립인 것으로 고려된다는 점에서 출력 공간을 “구조화되지 않은 것으로” 다룬다. Conditional GAN은 대신 structured loss(구조화된 손실 함수)를 사용한다. Structured loss는 출력의 joint configuration에 패널티를 준다. 이 논문의 넓은 부분에서 conditional random fields, the SSIM metric, feature matching, nonparametric losses, the convolutional pseudo-prior, 그리고 losses based on matching covariance statistics 등을 포함하는 방법을 사용해 이러한 종류의 손실을 다루었다. Conditional GAN은 손실이 학습되고, 이론적으로 출력과 타깃 사이의 서로 다른 모든 가능한 구조에 대해 패널티를 준다는 점에서 다르다.
Conditional GANs
이전부터의 작업들은 conditional GAN을 이산 레벨, 텍스트, 그리고 이미지에서 사용했다. 이미지 조건부 모델은 image prediction from a normal map, future frame prediction, product photo generation, 그리고 image generation from sparse annotation을 다루어 왔다. 몇몇 다른 논문들 또한 GAN을 이미지-이미지 매핑에 사용했으나, L2 규제와 같은 다른 항들에 의존하는 비조건 GAN만을 적용했다. 이러한 논문들은 inpainting, future state prediction, image manipulation guided by user constraints, style transfer, 그리고 superresolution에서 인상적인 결과를 달성해왔다. 우리의 프레임워크는 특정 응용에 해당하는 어떠한 것도 존재하지 않는다는 점에서 다르다.
우리의 방법은 또한 이전의 작업들과 생성자와 판별자에 대한 몇 가지 구조 선택에서 차이가 있다. 과거의 작업들과는 다르게, 우리의 생성자에 “U-Net”에 기반한 구조를 사용하고 판별자에는 이미지 패치 크기의 구조에만 패널티를 부여하는 convolutional “PatchGAN” 분류기를 사용한다. 비슷한 PatchGAN 구조는 예전에 local style statistics를 얻기 위해 제시되었다. 우리는 이 접근이 더 넓은 범위의 문제에서 효과적임을 보이며, 패치 크기를 바꾸는 것의 효과를 조사한다.
3. Method
GAN은 랜덤 노이즈 벡터 $z$에서 출력 이미지 $y$로의 매핑 $G:z\rightarrow y$를 학습하는 생성 모델이다. 이에 반해, conditional GAN은 관찰된 이미지 $x$와 랜덤 노이즈 벡터 $z$에서 $y$로의 매핑 $G:{x,z}\rightarrow y$를 학습한다. 생성자 $G$는 “실제” 이미지와 구별이 불가능한 출력을 만들어내도록, 판별자 $D$는 생성자의 “거짓” 이미지를 가능한 잘 탐지해내도록 경쟁적으로 훈련시킴으로 훈련된다. 이러한 훈련 과정은 Figure 2에 도식화되어 있다.
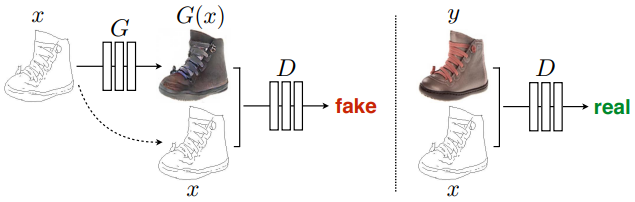
Figure 2: Conditional GAN을 edges→photo로 매핑하도록 훈련시키는 과정. 판별자 $D$는 거짓(생성자에 의해 합성되는 이미지)과 실제 이미지의 {edge, photo} 튜플을 분류하도록 학습한다. 생성자 $G$는 판별자를 속이도록 학습한다. 비조건 GAN과는 다르게 생성자와 판별자 모두 입력 edge map을 확인한다.
3.1. Objective
Conditional GAN의 목적 함수는 다음과 같이 표현된다:
\[\begin{equation} \mathcal{L}_{cGAN}(G,D)=\mathbb{E}_{x,y}[\log D(x,y)]+\mathbb{E}_{x,y}[\log (1-D(x,G(x,z)))], \end{equation}\]이 함수에서 $G$는 이 목적 함수를 최소화하려는 반면 그 상대 $D$는 이를 최대화하려고 한다. 다시 말해 $G^*=\arg\min_G\max_D\mathcal{L}_{cGAN}(G,D)$이다.
판별자에 조건을 두는 것의 중요성을 확인하기 위해, 판별자가 $x$를 관찰하지 않는, 비조건적인 변종을 비교한다:
\[\begin{equation} \mathcal{L}_{cGAN}(G,D)=\mathbb{E}_{x,y}[\log D(y)]+\mathbb{E}_{x,y}[\log (1-D(G(x,z)))]. \end{equation}\]이전의 접근들은 GAN의 목적 함수를 L2 거리와 같이 더 전통적인 손실 함수와 혼합하는 것이 효과적이라는 것을 찾아내었다. 판별자의 역할은 변하지 않지만, 생성자는 판별자를 속여야 할 뿐만 아니라, L2에 대해 믿을 만한 출력을 만들어내야 한다. L1이 L2보다 덜 흐린 출력을 만들어내므로, 이 옵션도 살펴본다:
\[\begin{equation} \mathcal{L}_{L1}(G)=\mathbb{E}_{x,y,z}[||y-G(x,z)||_1]. \end{equation}\]따라서 최종적인 목적 함수는 다음과 같다:
\[\begin{equation} G^*=\arg\min_G\max_D\mathcal{L}_{cGAN}(G,D)+\lambda \mathcal{L}_{L1}(G). \end{equation}\]$z$가 없이도 신경망은 $x$에서 $y$로의 매핑을 학습할 수 있으나 결정론적인 출력을 만들어낼 것이며, 그러므로 델타 함수가 아닌 다른 분포에 맞추지 못하게 된다. 과거의 conditional GAN은 이를 인지하고 생성자의 입력으로 기존의 $x$에서 가우시안 노이즈 $z$를 추가했다. 초기 실험에서 우리는 이러한 전략이 생성자가 단순히 노이즈를 무시하도록 학습하므로 효과적이지 않다는 것을 발견했으며 이는 Mathieu et al.의 논문의 견해와 일치한다. 대신에, 우리의 최종 모델에서는 노이즈를 오직 훈련과 테스트 모두에서 생성자의 몇 개 레이어에 적용되는 드롭아웃의 형태로만 가한다. 하지만 드롭아웃 노이즈를 가함에도 우리의 신경망의 출력에서는 조금의 확률(stochasticity)만이 관찰된다. 매우 확률적인 출력을 만들어내는 Conditional GAN을 설계하고 이를 통해 모델링하는 조건부 분포의 모든 엔트로피를 찾아내는 것은 현재 중요한 열린 문제로 남아있다.
3.2. Network architectures
우리는 [44]의 구조(DCGAN)를 우리의 생성자와 판별자 구조에 적용시켰다. 생성자와 판별자 모두 convolution-BatchNorm-ReLU 형태의 모듈을 사용한다. 온라인 보충 자료에 아래에서 다루는 중요 특징과 함께 구조에 관한 세부사항을 첨부했다.
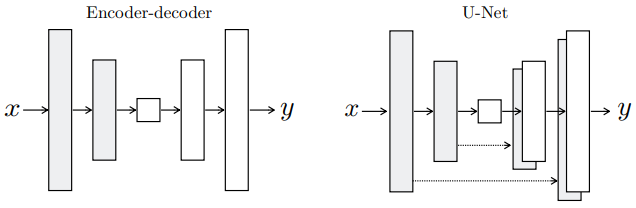
Figure 3: 생성자의 구조에 대한 두 가지 선택. “U-Net”은 인코더와 디코더 스택의 미러링된 레이어 사이의 skip connection을 사용하는 인코더-디코더이다.
3.2.1 Generator with skips
이미지-이미지 변환 문제의 특징은 고해상도의 입력 그리드를 고해상도의 출력 그리드로 매핑하는 것이다. 게다가, 우리가 고려하는 문제의 입력과 출력은 겉보기로 다르지만, 둘 다 동일한 기본 구조의 렌더링이다. 따라서 입력의 구조는 출력의 구조와 대략적으로 일치한다. 우리는 이러한 고려 사항에서 생성자 구조를 설계한다.
이 분야의 문제에 대한 이전의 많은 해결책은 인코더-디코더 신경망이었다. 이 신경망에서 입력은 점진적으로 다운샘플링하는 일련의 레이어를 거쳐간다. 이는 bottleneck 레이어까지 진행되며, 이 지점에서 다운샘플링 과정이 역전된다. 이러한 신경망은 모든 정보의 흐름이 bottleneck을 포함한 모든 레이어를 통과할 것을 요구한다. 많은 이미지 변환 문제에서는 입력과 출력 사이에 공유되는 많은 양의 저수준 정보가 있으며, 이 정보를 신경망을 통해 직접 전송하는 것이 바람직하다. 예를 들어 이미지 채색의 경우에 입력과 출력은 중요한 edge의 위치를 공유한다.
생성자에 정보의 병목을 우회할 방법을 제공하기 위해, 우리는 “U-Net”의 일반적인 모습과 같이 skip connection을 추가했다. 특별히, 우리는 각각의 레이어 $i$와 레이어 $n-i$ ($n$은 모든 레이어의 수) 사이에 skip connection을 추가했다. 각각의 skip connection은 간단히 레이어 $i$의 모든 채널을 레이어 $n-i$의 모든 채널에 연결한다.
3.2.2 Markovian discriminator (PatchGAN)
L2와 L1 손실이 이미지 생성 문제에서 흐린 결과를 생성해낸다는 사실은 잘 알려져 있다. 이러한 손실들이 고주파수의 선명도를 얻어내도록 하지는 못하지만, 많은 경우에 저주파수의 특징은 정확하게 얻어낸다. 따라서 전체적으로 저주파수를 잡아내기 위해 완전히 새로운 프레임워크를 만들어낼 필요 없이 L1을 사용한다.
이는 GAN 판별기를 고주파수의 정확성만을 모델링하도록 하고, 저주파수 정확성은 L1 항에 의존하는 동기가 된다 (Eqn. 4). 고주파수를 모델링하기 위해서, 관심을 지역적 이미지 패치의 구조에만 두는 것이 충분하다. 따라서 패치의 크기 안에서만 패널티를 부여하는 PatchGAN 판별자 구조를 설계한다. 이 판별자는 이미지 안의 각 $N\times N$ 패치가 실제인지 거짓인지를 분류하려 한다. 우리는 이 판별자를 이미지 전체에 걸쳐 합성곱으로 실행하며, 모든 결과를 평균하여 $D$의 궁극적인 출력을 제공한다.
Section 4.4에서, 우리는 $N$이 이미지의 전체 크기보다 매우 작아도 여전히 고품질의 결과를 만들어냄을 설명한다. 이러한 사실은 더 작은 PatchGAN은 더 적은 파라미터를 가지고, 더 빠르게 실행되며, 임의의 큰 이미지에 적용될 수 있으므로 더 유리함을 보여준다.
이러한 판별자는 패치의 직경보다 멀리 떨어진 픽셀들 사이의 독립성을 가정하며 이미지를 Markov random field로 효과적으로 모델링한다. 이 연결은 이전에 [38]에서 탐색되었으며 질감 모델 [17, 21] 및 스타일 모델 [16, 25, 22, 37]에서도 일반적인 가정이다. 따라서 PatchGAN을 질감/스타일 손실의 형태로 이해할 수 있다.
3.3. Optimization and inference
신경망을 최적화하기 위해 원래의 GAN 논문에서의 일반적인 접근법을 따른다. 즉 $D$와 $G$의 경사 하강법 스텝을 번갈아 진행한다. 원래의 GAN 논문에서 제안한 대로, $G$가 $\log (1-D(x, G(x,z))$를 최소화하는 대신 $\log D(x, G(x,z))$를 최대화하도록 훈련시킨다. 거기에 더해, $D$를 최적화하면서 목적 함수를 2로 나누어 $G$에 비해서 $D$가 학습하는 속도를 늦춘다. 우리는 미니배치 SGD를 사용하고 학습률 0.0002, 모멘텀 파라미터 $\beta_1=0.5,\ \beta_2=0.999$의 Adam 최적화기를 적용했다.
추론시에는 학습 단계와 정확히 같은 방법으로 생성자 신경망을 실행한다. 이는 테스트에서 드롭아웃을 적용한다는 점, 그리고 학습 배치가 아닌 테스트 배치의 통계량을 사용하여 배치 정규화를 적용한다는 점에서 일반적인 사용과는 다르다. 배치 정규화에 대한 이러한 접근은 배치 크기가 1일 때 “인스턴스 정규화”라고 부르며, 이미지 생성 작업에서 효과적임이 입증되었다. 연구에 따라 1에서 10 사이의 배치 크기를 사용한다.
4. Experiments
Conditional GAN의 일반성을 탐구하기 위해, 사진 생성과 같은 그래픽스 작업과 시멘틱 분할과 같은 비전 작업을 포함하는 다양한 작업과 데이터셋에서 우리의 방법을 테스트한다:
- Semantic labels↔photo, Cityscapes dataset.
- Architectural labels→photo, trained on CMP Facades.
- Map↔aerial photo, trained on data scraped from Google Maps.
- BW→color photos, trained on ILSVRC.
- Edges→photo, trained on data from [65] and [60]; binary edges generated using the HED edge detector plus postprocessing.
- Sketch→photo: tests edges→photo models on humandrawn sketches from [19].
- Day→night, trained on [33].
- Thermal→color photos, trained on data from [27].
- Photo with missing pixels→inpainted photo, trained on Paris StreetView from [14].
각각의 데이터셋에서의 훈련의 세부사항은 온라인 보충 자료에 제공되어 있다. 모든 겨우에서 입출력은 간단한 1-3 채널의 이미지이다. 수량적인 결과는 Figures 8, 9, 11, 10, 13, 14, 15, 16, 17, 18, 19, 20에서 볼 수 있다. 몇 가지 실패는 Figure 21에서 보여주고 있다. 더 포괄적인 결과는 https://phillipi.github.io/pix2pix/에서 확인할 수 있다.
Data requirements and speed
작은 크기의 데이터에서도 자주 그럴듯한 결과를 얻을 수 있다. 우리가 사용하는 facade 데이터셋은 단지 400 장의 이미지를 가지고 있으며 (Figure 14), day-night 훈련 세트는 오직 91개의 웹캠으로 구성된다 (Figure 15). 이러한 크기의 데이터셋에서는 훈련이 매우 빨리 진행될 수 있다. 예를 들어, Figure 14에 소개된 결과는 하나의 Pascal Titan X GPU에서 2시간 미만의 훈련 시간이 소요되었다. 테스트에서, 이 GPU로 초 이하의 시간에서 모든 모델이 잘 실행된다.
4.1. Evaluation metrics
합성된 이미지의 품질을 평가하는 것은 어렵고 열려 있는 문제이다. 픽셀당 MSE와 같은 전통적인 측정 항목들은 결과의 결합 통계량을 평가하지 않으며, 따라서 구조화된 손실이 얻으려는 구조를 측정하지 않는다.
우리의 결과에 대한 시각적인 품질을 더 전체적으로 평가하기 위해 우리는 두 가지 전략을 채택한다. 먼저, 우리는 Amazon Mechanical Turk(AMT, 참조)를 통해서 “실제 대 거짓” 지각 연구를 진행한다. 채색과 사진 생성과 같은 그래픽스 문제에 있어서, 인간 관찰자가 느끼는 그럴듯함이 자주 궁극적인 목표가 된다. 따라서, 우리는 지도 생성, 항공 사진 생성, 그리고 이미지 채색을 이 접근법을 사용하여 테스트했다.
두번째로, 우리는 합성된 도시의 풍경이 충분히 현실적이어서 일반적인 지각 시스템이 풍경 속의 객체들을 인지할 수 있는지를 측정한다. 이 측정 항목은 [52]의 “inception score”, [55]의 객체 탐지 평가, 그리고 [62]와 [42]의 “semantic interpretability”와 비슷하다.
AMT perceptual studies
AMT 실험에서, 우리는 [62]의 프로토콜을 따랐다. Turker(AMT에서 제시된 업무를 수행하는 불특정 노동자)들은 우리의 알고리즘이 생성한 “거짓” 이미지와 “실제” 이미지를 비교하는 일련의 작업을 받았다. 각 시험에서, 각각의 이미지는 1초 동안 보여지고 이미지가 사라진 후 Turker들은 제한없는 시간 동안 거짓 이미지를 찾아야 했다. 각 세션에서 첫 10개의 이미지는 연습으로 Turker들은 피드백을 받는다. 그 이후 주 실험에서의 40개의 시도 동안에는 피드백을 받지 않는다. 각 세션마다 하나의 알고리즘을 테스트했으며, Turker들 또한 각자 한 가지 알고리즘만을 테스트하도록 했다. 50명 정도의 Turker들이 각 알고리즘을 평가했다. [62]와 다르게, vigilance trial은 포함하지 않았다. 우리의 채색 실험에서, 실제와 거짓 이미지는 똑같은 그레이스케일 입력에서 만들어졌다. Map↔aerial photo 실험에서는, 작업을 더 어렵게 하고 floor-level result를 피하기 위해 실제와 거짓 이미지를 같은 입력으로 만들지 않았다. Map↔aerial photo 실험에서 256×256 해상도의 이미지를 사용하여 훈련시켰지만, 테스트에서는 fully-convolutional translation을 적용하여 512×512의 이미지를 사용했고, 다운샘플링하여 Turker들에게 256×256의 이미지를 제시했다. 채색에서는 훈련과 테스트 모두에 256×256 해상도 이미지를 사용했으며 Turker들에게도 같은 해상도의 결과를 제시했다.
“FCN-score”
생성 모델의 수량적으로 평가하는 것이 도전적인 것으로 알려져 있지만, 최근의 연구들은 생성된 자극의 식별 가능성을 사전 훈련된 시멘틱 분류기들을 사용하여 pseudo-metric으로 측정하는 시도를 보였다. 이에 대한 직관은 생성된 이미지가 현실적이라면, 실제 이미지들로 훈련된 분류기가 합성된 이미지 또한 올바르게 잘 분류해낼 것이라는 데에 있다. 이를 위하여 우리는 시멘틱 세그멘테이션을 위해 유명한 FCN-8s 구조를 적용했고 Cityspaces 데이터셋에 훈련시켰다. 그 후 우리가 레이블에 따라 합성한 사진에 레이블에 대한 분류 정확도를 계산했다.
4.2. Analysis of the objective function
Eqn. 4의 어떠한 요소가 중요한 것인가? Ablation study(참조)를 진행하면서 L1 항, GAN 항을 분리해보았으며, cGAN과 GAN의 판별자를 비교해보았다.
에 있다.](/assets/images/2021-09-14/Untitled%203.png)
Figure 4: 다른 손실들은 서로 다른 품질의 결과를 만들도록 유도한다. 각 열은 다양한 손실에서 훈련된 결과를 보여준다. 추가적인 예시는 https://phillipi.github.io/pix2pix에 있다.
Figure 4는 두 가지 labels→photo 문제에서 이러한 변형에 따른 효과들을 보여준다. L1만 사용하는 것은 적절하지만 흐릿한 결과물을 보여준다. cGAN만 사용하는 것(Eqn. 4에서 $\lambda=0$으로 설정)은 훨씬 명확한 결과를 보여주나, 특정한 적용 상황에서는 인위적인 시각적 구조를 만들어낸다. 두 항을 모두 사용하면 ($\lambda = 100$으로 설정) 이러한 구조를 줄일 수 있다.
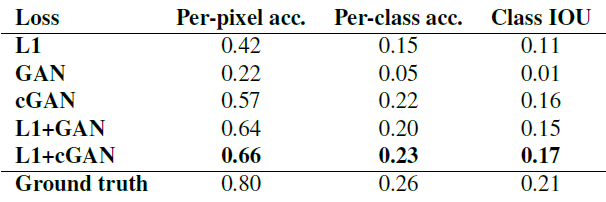
Table 1: 다른 손실에서의 FCN-점수. Cityscapes labels↔photo에서 측정함.
우리는 이러한 관찰을 Cityspaces labels→photo 작업에서 FCN-점수를 사용하여 수량화했다 (Table 1). GAN 기반의 목적 함수가 더 높은 점수를 얻어내는데, 이는 합성된 이미지가 더 인식 가능한 구조를 지닌다는 것을 보여준다. 우리는 또한 판별자에게서 조건을 없애는 것의 효과를 테스트했다 (GAN 란). 이 경우에, 손실 함수는 입출력간의 불일치에 패널티를 부여하지 않고 오직 출력이 현실적인지만 살핀다. 이러한 변형은 나쁜 성능을 보인다. 결과를 검사한 결과, 생성자가 입력 사진에 관계 없이 거의 똑같은 출력을 만들어내도록 축소되었음을 알 수 있었다. 이 경우에서 손실이 입력과 출력 사이의 일치하는 품질을 측정하고, cGAN이 GAN보다 상당히 좋은 성능을 보여준다는 점이 중요하다. 그러나 L1 항을 추가하는 것 또한 출력이 입력을 인지하도록 하는데, 이는 L1 손실이 입력과 일치하는 실제 출력과 일치하지 않을 수 있는 합성된 출력 사이의 거리에 패널티를 부여하기 때문이다. 따라서 L1+GAN 또한 입력 레이블 맵을 인지하는 현실적인 렌더링을 생성하는데 효과적이다. 모든 항을 더한 L1+cGAN도 비슷하게 좋은 성능을 보인다.
Colorfulness
Conditional GAN의 두드러진 효과는 입력 레이블 맵에 존재하지 않는 부분에서도 가상의 공간 구조를 만들어내어 명확한 이미지를 만들어낸다는 점이다. cGAN이 스펙트럼 차원에서의 “선명화(sharpening)”에 유사한 영향을 미친다고 생각할 수 있다. 즉 이미지를 더욱 화려하게 만드는 것이다. L1이 edge를 정확히 어디에 위치해야 할지 불확실할 때 흐릿함을 만들어내는 것처럼, 픽셀이 가능한 값들 중 정확히 어느 색상값을 취해야 할지 불학실할 때 평균적인 회색을 만들어낸다. 특히, 가능한 색상에 대한 조건부 확률 밀도 함수의 중앙값을 선택함으로 L1은 최소화될 것이다. 한편 적대적 손실은 이론상 회색 출력이 비현실적임을 알 수 있으며, 실제 색상 분포에 맞추도록 할 수 있다. Figure 7에서, 우리의 cGAN이 Cityspaces 데이터셋에서 실제로 이 효과를 달성하는지를 조사했다. 그림에서 Lab의 색상 공간에서의 출력 색상값의 주변 분포(marginal distribution)를 보여주고 있다. 실제 분포는 점선으로 표시되어 있다. L1이 실제보다 더 좁은 분포를 만들어낸다는 사실은 명백하며, 이는 L1이 평균적인 회색을 만들어낸다는 가설을 입증한다. 한편, cGAN을 사용하는 것은 출력의 분포를 사실에 가깝게 만들어낸다.
4.3. Analysis of the generator architecture

Figure 5: 인코더-디코더에 skip connection을 추가하여 만든 “U-Net”이 훨씬 좋은 품질의 결과를 보여준다.

Table 2: 다른 생성자 구조와 목적 함수에서의 FCN-점수. Cityscapes labels↔photo에서 측정함. (U-Net (L1-cGAN) 점수는 다른 구조들이 배치 사이즈가 1인 반면 10으로 설정했고, 학습마다 random variation을 두었기 때문에 다른 구조들과 다르다.)
U-Net 구조는 저수준의 정보가 신경망을 가로지르도록 할 수 있다. 이 사실이 더 나은 결과를 만들어낼 수 있는가? Figure 5와 Table 2는 도시 경관 생성에서 U-Net과 인코더-디코더를 비교하고 있다. 인코더-디코더는 간단히 U-Net의 skip-connection을 끊어냄으로 만들 수 있다. 인코더-디코더는 우리의 실험에서 현실적인 이미지를 생성하도록 학습할 수 없다. U-Net의 이점은 conditional GAN에 국한되어 보여지지 않는다. U-Net과 인코더-디코더 모두 L1 손실에 학습되면 U-Net은 여전히 더 나은 결과를 보여준다.
4.4. From PixelGANs to PatchGANs to ImageGANs
에서 확인할 수 있다.](/assets/images/2021-09-14/Untitled%207.png)
Figure 6: 패치 크기에 따른 변형들. 출력의 불확실성은 다양한 손실 함수들에 따라 다르게 나타난다. L1에서 불확실한 영역은 흐리고 채도가 낮다. 1×1 PixelGAN은 더 나은 색상 다양성을 보여주나 공간 통계량에 영향을 미치지는 않는다. 16×16 PatchGAN은 지역적으로 명확한 결과를 보여주지만, 관찰할 수 없는 크기에서 타일화된 인공 구조가 만들어진다. 70×70 PatchGAN은 공간과 스펙트럼(색상) 차원에서 옳지 않더라도 명확한 출력을 만들어낸다. 286×286 PatchGAN은 70×70 PatchGAN과 시각적으로 비슷한 출력을 만들어내지만, FCN-점수에서는 조금 낮은 품질을 보여준다 (Table 3). 추가적인 예시는 https://phillipi.github.io/pix2pix/에서 확인할 수 있다.
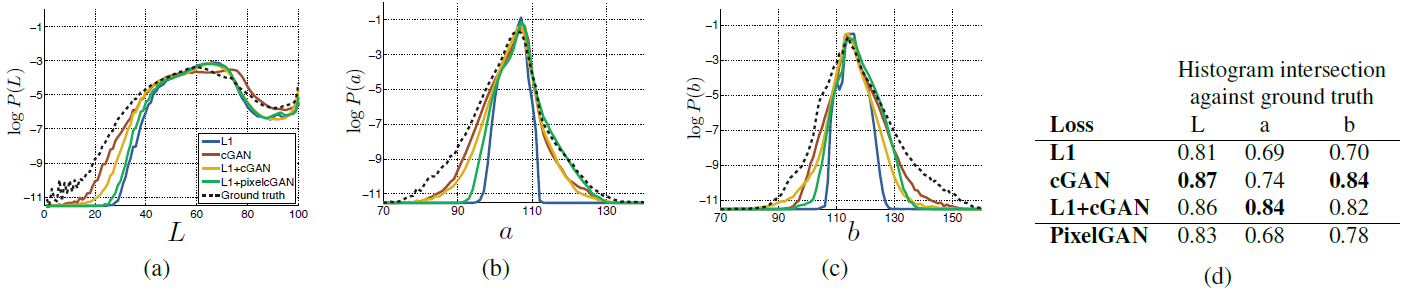
Figure 7: Cityscapes 데이터셋에서 테스트한 cGAN의 색상 분포 일치 특성. 히스토그램 교차 점수는 (낮은 확률 영역의 차이를 강조하는) 로그 확률을 보이는 그림에서, 감지할 수 없는 높은 확률 영역에서의 차이에 좌우된다.
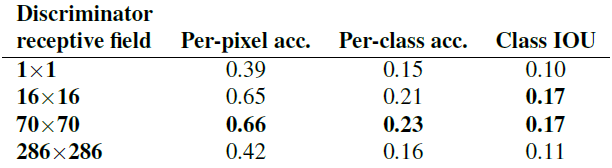
Table 3: 판별자의 다른 receptive field 크기에 따른 FCN-점수. Cityscapes labels↔photo에서 측정함. 입력 이미지는 256×256 픽셀이며 이보다 더 큰 receptive field의 경우 zero padding을 사용했다.
우리는 판별자의 receptive field의 패치 크기 $N$에 따른 영향을 1×1 “PixelGAN”부터 286×286 “ImageGAN”까지 비교하며 테스트했다. Figure 6은 이 분석의 질적인 결과를 보여주며 Table 3은 패치 크기에 따른 영향을 FCN-점수를 사용하여 수량화했다. 이 논문의 모든 다른 부분에서는, 특정되지 않았을 때, 모든 실험은 70×70 PatchGAN을 사용했으며, 이 section에서는 모든 실험에 L1+cGAN이 사용되었음을 밝힌다.
PixelGAN은 출력의 공간적인 선명도에서 아무런 영향을 미치지 못하나 색상을 더 화려하게 했다 (Figure 7에서 수량화되었다). 예를 들어, Figure 6의 버스는 신경망이 L1에서 훈련되었을 때 회색으로 칠해졌으나, PixelGAN 손실에서는 빨간색으로 칠해졌다. 색상 히스토그램 일치는 이미지 처리에서 일반적인 문제이며, PixelGAN이 기대되는 경량 솔루션이 될 수 있다.
16×16 PatchGAN을 사용하는 것은 선명한 출력을 촉진하는데 충분하며, 좋은 FCN-점수를 얻어내지만 타일화된 인공 구조를 만들어낸다. 70×70 PatchGAN은 이러한 구조를 완화하며 조금 더 나은 점수를 얻는다. 패치 크기를 완전한 286×286으로 설정한 PatchGAN에서는 출력의 시각적인 질이 향상되어 보이지 않으며, 상대적으로 더 낮은 FCN-점수를 얻는다 (Table 3). 이는 아마도 ImageGAN이 70×70 PatchGAN보다 더 많은 파라미터와 깊이를 가지며 훈련이 더 어렵기 때문일 것이다.
Fully-convolutional translation
PatchGAN의 이점은 고정된 크기의 패치를 가진 판별자가 임의의 큰 이미지에 적용될 수 있다는 점이다. 우리는 또한 생성자를 훈련된 이미지보다 큰 이미지들에 convolution을 사용하여 적용시킬 수 있다. 우리는 이를 map↔aerial photo 작업에서 테스트했다. 생성자를 256×256 이미지에서 훈련시킨 후에, 512x512 이미지에서 테스트한다. Figure 8의 결과에서 이러한 접근법의 효과를 설명하고 있다.
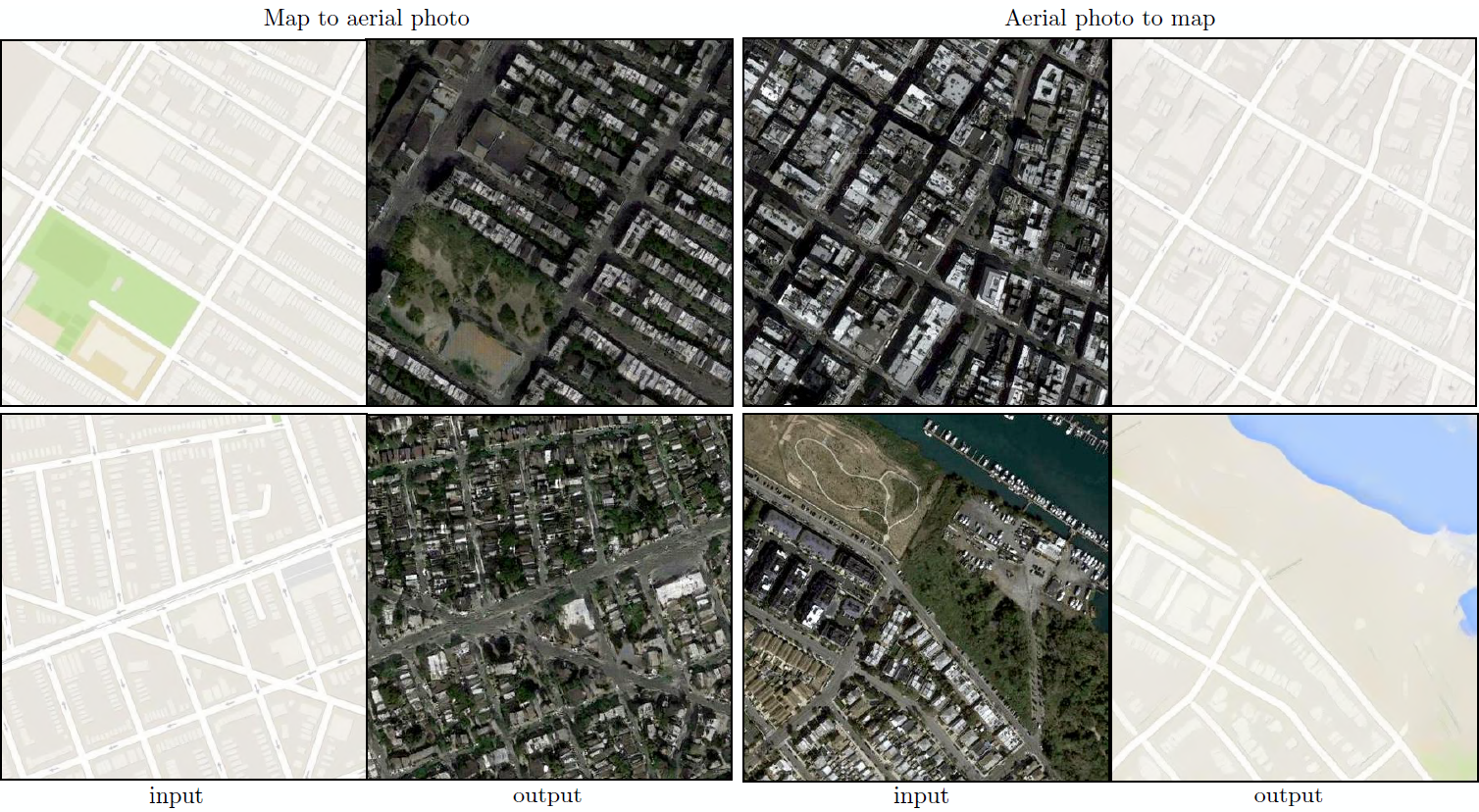
Figure 8: Google Maps에서의 512×512 해상도에서의 결과 예시 (모델은 256×256 해상도의 이미지에서 훈련되었고 테스트 시간에서 더 큰 이미지들을 convolution을 사용하여 실행했다). 선명도를 높이기 위해 대비를 조정했다.
4.5. Perceptual validation

Table 4: AMT에서 진행한 maps↔aerial photos의 “실제 vs 거짓” 테스트.
우리는 map↔aerial photograph와 grayscale→color 작업의 결과에 대한 지각적인 현실성을 검증했다. Map↔photo에 대한 AMT 실험의 결과는 Table 4에서 확인할 수 있다. 우리의 방법으로 생성된 항공 사진들은 참가자들을 18.9%의 시도에서 속였다. 이는 흐린 사진을 만들어내어 참가자들을 거의 속이지 못한 L1의 baseline보다 상당히 높은 수준이다. 이와는 대조적으로, photo→map 방향에서는 우리의 방법이 참가자의 6.1%의 시도만 속일 수 있었으며, 이는 (부트스트랩 테스트에 기반한) L1 baseline의 성능과 크게 다르지는 않았다. 이는 아마 소수의 구조적 오류가 정밀한 기하적 배열을 가진 지도 상에서 볼 때 더 무질서적인 항공 사진보다 더 가시적이기 때문일 것이다.
![Figure 9: Conditional GAN과 [62]의 L2 회귀 및 [64]의 전체적인 방법 (재균형을 통한 분류) 사이의 채색 결과 비교. cGAN은 설득력있는 채색을 보여주지만 (첫 두 행), 그레이스케일 또는 낮은 채도의 결과를 만들어내는 공통된 실패 모드를 가진다 (마지막 행).](/assets/images/2021-09-14/Untitled%2012.png)
Figure 9: Conditional GAN과 [62]의 L2 회귀 및 [64]의 전체적인 방법 (재균형을 통한 분류) 사이의 채색 결과 비교. cGAN은 설득력있는 채색을 보여주지만 (첫 두 행), 그레이스케일 또는 낮은 채도의 결과를 만들어내는 공통된 실패 모드를 가진다 (마지막 행).
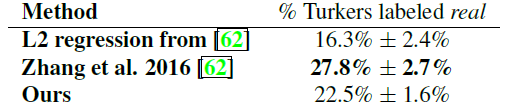
Table 5: AMT에서 진행한 채색의 “실제 vs 거짓” 테스트.
우리는 ImageNet에서 채색을 훈련했으며, [62, 35]에서 소개된 테스트 분할을 사용하여 테스트를 진행했다. L1+cGAN 손실을 사용한 방법은 참가자들을 22.5%의 시도에서 속였다 (Table 5). 우리는 또한 [62]의 L2를 사용한 방법의 변형으로 [62]의 결과를 테스트했다 (자세한 내용은 [62]를 참조할 것). Conditional GAN은 [62]의 L2 변형과 비슷한 점수를 받았지만 (부트스트랩 테스트로도 유의하지 않은 차이를 보였다), 우리의 실험에서 참가자들을 27.8%에서 속인 [62]의 전체 방법에는 미치지 못했다. 그들의 방법은 특별히 채색을 잘 해내도록 설계되었다.
4.6. Semantic segmentation
Conditional GAN은 이미지 처리나 그래픽 작업에서 흔히 볼 수 있듯이 출력이 상당히 세부적이거나 실제 사진에 가까운 문제에 효과적인 것으로 보인다. 그렇다면 시멘틱 세그멘테이션같이 출력이 입력보다 덜 복잡한 비전 문제는 어떠할까?

Figure 10: Conditional GAN을 시멘틱 세그멘테이션에 적용한 결과. cGAN은 얼핏 보기에 ground truth처럼 보이는 선명한 이미지를 만들어내지만, 사실 많은 작은 거짓 객체를 포함한다.
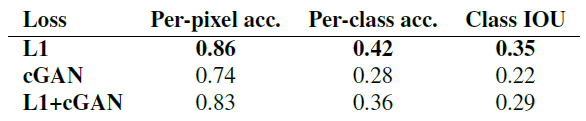
Table 6: Cityscapes에서 photo→labels의 성능.
이 문제를 테스트하기 위해, 우리는 (L1 손실을 포함하거나 하지 않은) cGAN을 cityscapes에서 photo→labels 작업에 훈련시켰다. Figure 10에서 질적인 결과를 볼 수 있으며, 수량적인 분류 정확도는 Table 6에 기록되어 있다. 흥미롭게도, L1 없이 훈련된 cGAN은 이 문제를 합리적인 수준의 정확도로 해결할 수 있다. 우리가 아는 바로는 이 사실이 GAN이 연속적인 값의 변화를 보이는 “이미지”보다는, 거의 이산적인 구분을 보이는 “레이블”을 성공적으로 생성해냄을 입증하는 것이다. 하지만 cGAN이 어느 정도 성취를 보이더라도, cGAN은 이 문제를 해결하는데 완벽한 메소드는 아니다. 간단히 보아도, L1 회귀를 사용하는 것이 cGAN을 사용하는 것보다 Table 6에서 볼 수 있듯이 더 나은 점수를 얻을 수 있다. 우리는 비전 문제의 경우, (실제 정보에 근접한 출력을 예측하는) 목표는 그래픽 작업에 비해 덜 모호할 수 있으며 L1과 같은 재구성 손실은 대부분 이와 같은 작업에 충분하다고 주장한다.
4.7. Community-driven Reseach
우리의 논문과 pix2pix 코드베이스가 처음 공개된 이후, 컴퓨터 비전 및 그래픽 전문가와 비주얼 아티스트 등을 포함한 트위터 커뮤니티는 기존 논문의 범위를 훨씬 벗어나 다양하고 새로운 이미지-이미지 변환 작업에 우리의 프레임워크를 성공적으로 적용했다. Figure 11과 Figure 12는 #pix2pix 해시태그 중 몇 가지 예시만을 보여주고 있는데, Background removal, Pallete generation, Sketch→Portrait, Sketch→Pokemon, “Do as I do” pose transfer, Learning to: Gloomy Sunday, 그리고 상당히 인기 있는 #edges2cats와 #fotogenerator 등이다. 이러한 어플리케이션들이 창의적인 프로젝트이고, 통제된 과학적 조건 하에 만들어지지 않았으며, 우리가 공개한 pix2pix 코드에 일부 수정을 가한 정도로 만들어졌다는 것이 중요하다. 그럼에도 불구하고, 그들은 이미지-이미지 변환 문제에 대한 일반적인 상품 도구로서의 우리의 접근법의 가능성을 보여준다.
![Figure 11: 우리의 `pix2pix` 코드베이스에 기초한 온라인 커뮤니티에서 개발된 예제 어플리케이션: *#edges2cats* [3] by Christopher Hesse, *Background removal* [6] by Kaihu Chen, *Palette generation* [5] by Jack Qiao, *Sketch*→*Portrait* [7] by Mario Klingemann, *Sketch*→*Pokemon* [1] by Bertrand Gondouin, *“Do As I Do” pose transfer* [2] by Brannon Dorsey, and *#fotogenerator* by Bosman et al. [4].](/assets/images/2021-09-14/Untitled%2016.png)
Figure 11: 우리의 pix2pix 코드베이스에 기초한 온라인 커뮤니티에서 개발된 예제 어플리케이션: #edges2cats [3] by Christopher Hesse, Background removal [6] by Kaihu Chen, Palette generation [5] by Jack Qiao, Sketch→Portrait [7] by Mario Klingemann, Sketch→Pokemon [1] by Bertrand Gondouin, “Do As I Do” pose transfer [2] by Brannon Dorsey, and #fotogenerator by Bosman et al. [4].
5. Conclusion
이 논문의 결과는 조건부 적대적 신경망이 많은 이미지-이미지 변환 작업, 특히 상당히 구조화된 그래픽 출력을 포함하는 작업에 대한 유망한 접근법임을 제시한다. 이러한 신경망은 주어진 작업과 데이터에 손실을 학습하여 다양한 환경에 적응할 수 있다.
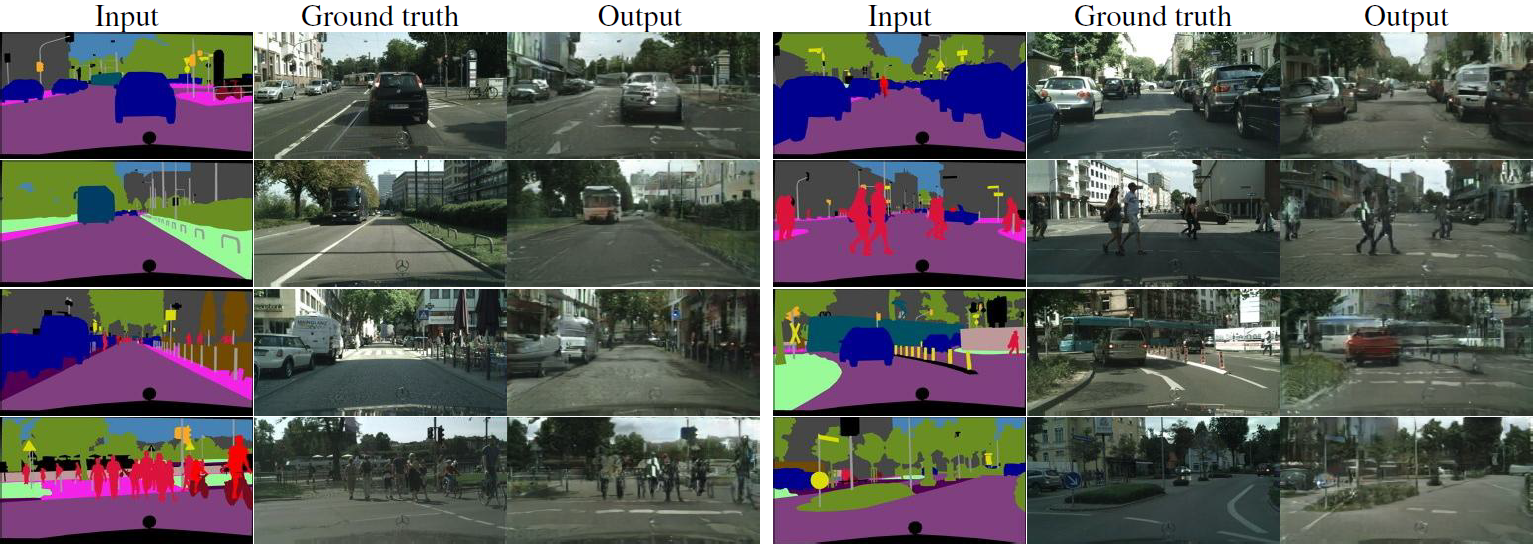
Figure 13: Cityscapes labels→photo에서 실제와 비교한 우리의 방법의 결과 예시.

Figure 14: Facades labels→photo에서 실제와 비교한 우리의 방법의 결과 예시.

Figure 15: Day→night에서 실제와 비교한 우리의 방법의 결과 예시.

Figure 16: Automatically detected edges→handbags에서 실제와 비교한 우리의 방법의 결과 예시.

Figure 17: Automatically detected edges→shoes에서 실제와 비교한 우리의 방법의 결과 예시.
![Figure 18: [19]에서 인간이 그린 스케치에 적용된 Edges→photo 모델의 추가 결과. 모델은 automatically detected edges에서 훈련되었지만, 인간의 그림으로 일반화되었다.](/assets/images/2021-09-14/Untitled%2022.png)
Figure 18: [19]에서 인간이 그린 스케치에 적용된 Edges→photo 모델의 추가 결과. 모델은 automatically detected edges에서 훈련되었지만, 인간의 그림으로 일반화되었다.
![Figure 19: Paris StreetView 데이터셋 [14]에서 [43]과 비교환 사진 복원 결과의 예시. 이 실험은 예측된 픽셀이 입력 정보와 기하학적으로 정렬되지 않는 경우에도 U-Net 구조가 효과적일 수 있다는 사실을 보여준다 — 중앙의 구멍을 채우는 데 사용되는 정보를 사진의 주변에서 얻어내야 한다.](/assets/images/2021-09-14/Untitled%2023.png)
Figure 19: Paris StreetView 데이터셋 [14]에서 [43]과 비교환 사진 복원 결과의 예시. 이 실험은 예측된 픽셀이 입력 정보와 기하학적으로 정렬되지 않는 경우에도 U-Net 구조가 효과적일 수 있다는 사실을 보여준다 — 중앙의 구멍을 채우는 데 사용되는 정보를 사진의 주변에서 얻어내야 한다.
![Figure 20: [27]의 데이터셋에서 thermal image를 RGB 사진으로 변환하는 결과의 예시.](/assets/images/2021-09-14/Untitled%2024.png)
Figure 20: [27]의 데이터셋에서 thermal image를 RGB 사진으로 변환하는 결과의 예시.
를 참조하라.](/assets/images/2021-09-14/Untitled%2025.png)
Figure 21: 실패 사례. 각각의 이미지 쌍은 왼쪽에 입력, 오른쪽에 출력을 표시한다. 이 예제들은 우리의 작업에서 최악의 결과들 중 하나로 선택되었다. 일반적인 실패는 입력 이미지의 희박한 영역에서의 인공 구조나, 비정상적인 입력 처리의 어려움을 포함한다. 보다 포괄적인 결과를 보려면 https://phillipi.github.io/pix2pix를 참조하라.
6 Appendix
6.1. Network architectures
우리는 [44]의 신경망 구조를 적용했다. 모델의 코드는 https://phillipi.github.io/pix2pix/에서 확인할 수 있다. Ck를 k개의 필터를 가진 Convolution-BatchNorm-ReLU 레이어라고 하자. CDk는 50%의 드롭아웃 비율을 가진 Convolution-BatchNorm-ReLU 레이어를 의미한다. 모든 Convolution은 stride가 2인 4×4 spatial filter들이다. 인코더와 판별자에 있는 convolution은 2로 나누어 다운샘플링되고, 반면에 디코더에서는 2로 곱해져 업샘플링된다.
6.1.1 Generator architectures
인코더-디코더 구조는 다음을 포함한다:
- 인코더:
C64-C128-C256-C512-C512-C512-C512-C512 - 디코더:
CD512-CD512-CD512-C512-C256-C128-C64
디코더의 마지막 레이어 이후에, convolution은 출력 채널(일반적으로 3이며, 채색에서는 2)의 수에 매핑된 다음 Tanh 함수를 통과한다. 위의 표기에 대한 예외로, BatchNorm은 인코더의 첫 C64 레이어에 적용되지 않는다. 인코더의 모든 ReLU는 slope가 0.2인 leakyReLU인 반면, 디코더는 leakyReLU가 아니다.
U-Net 구조는 기본적으로 인코더-디코더 구조와 같으나, 인코더의 각 레이어 $i$와 디코더의 레이어 $n-i$ 사이의 skip connection이 존재한다 (이 때 $n$은 레이어의 총 개수이다). Skip connection은 레이어 $i$에서 레이어 $n-i$로 활성화 함수를 연결한다.
- U-Net 디코더:
CD512-CD1024-CD1024-C1024-C1024-C512-C256-C128
6.1.2 Discriminator architectures
70×70 판별자 구조는 C64-C128-C256-C512이다.
마지막 레이어 이후에, convolution은 1차원 출력 매핑과 시그모이드 함수를 통과한다. 위 표기에 대한 예외로, BatchNorm은 첫 C64 레이어에 적용되지 않는다. 모든 ReLU는 slope가 0.2인 LeakyReLU이다.
모든 다른 다른 판별자는 receptive field의 크기에 따라 다른 깊이를 가진 동일한 기본 구조를 따른다.
- 1×1 판별자:
C64-C128(이 특별한 경우에, 모든 convolution은 1×1 spatial filter이다) - 16×16 판별자:
C64-C128 - 286×286 판별자:
C64-C128-C256-C512-C512-C512
6.2. Training details
256×256 입력 이미지를 286×286으로 조정하는데 random jitter를 사용하고 무작위로 잘라내서 다시 256×256의 크기로 만들었다.
모든 신경망은 처음부터 훈련되었다. 가중키는 평균이 0이고 표준편차가 0.02인 가우시안 분포에서 초기화되었다.
Cityscapes labels→photo
Cityscapes 데이터셋의 2975개의 훈련 이미지를 200 에포크동안 random jitter와 mirroring을 사용하여 훈련시켰다. Cityscapes 검증 세트를 테스트에 사용했다. U-Net과 인코더-디코더 구조를 비교하기 위해 배치 크기를 10으로 설정한 반면, 목적 함수에 대한 실험을 위해서는 1을 사용했다. 우리는 1의 배치 크기가 U-Net에서 더 나은 결과를 보이나 인코더-디코더에는 부적합하다는 것을 발견했다. 이는 신경망의 모든 레이어에 배치 정규화를 적용했으며, 배치 크기가 1인 경우 이 연산이 bottleneck 레이어의 활성화 함수를 0으로 만들기 때문이다. I-net은 bottleneck을 건너뛸 수 있으나 인코더-디코더는 그럴 수 없으므로, 인코더-디코더는 배치 크기를 1보다 크게 설정해야 한다. 대안은 bottleneck 레이어에서 배치 정규화를 제외하는 것이다.
Architectural labels→photo
[45]에서 400개의 훈련 이미지를 200 에포크동안 배치 크기 1로, random jitter와 mirroring을 사용하여 훈련시켰다. 데이터는 무작위로 훈련과 테스트로 분할되었다.
Maps↔aerial photograph
Google Maps에서 스크래핑한 1096개의 훈련 이미지를 200 에포크동안 배치 크기 1로, random jitter와 mirroring을 사용하여 훈련시켰다. 이미지는 뉴욕과 그 주변에서 샘플링되었다. 데이터는 (테스트 세트에서 훈련 세트의 픽셀이 나타나지 않도록 하기 위한 버퍼 영역을 포함한) 샘플링 영역의 중위도에 대해 훈련과 테스트로 분할되었다.
BW→color
Imagenet 훈련 세트의 120만 훈련 이미지를 6 에포크 정도 동안 배치 크기 4로, mirroring만을 사용하여 훈련시켰다. Imagenet 검증 세트의 부분 집합에서 [62]와 [35]의 프로토콜을 따르며 테스트했다.
Edges→shoes
UT Zappos50K 데이터셋의 5만여 개의 훈련 이미지를 15 에포크동안 배치 크기 4로 훈련시켰다. 데이터는 훈련과 테스트 세트로 무작위 분할되었다.
Day→night
[33]의 91개의 웹캠에서 추출된 17823개의 훈련 이미지를 17 에포크동안 배치 크기 4로, random jitter와 mirroring을 사용하여 훈련시켰다. 91개의 웹캠을 훈련으로, 10개의 웹캠을 테스트로 사용했다.
Thermal→color photos
[27]의 00-05 세트에서 36609개의 훈련 이미지를 10 에포크동안 배치 크기 4로 훈련시켰다. 06-11 체트의 이미지들을 테스트로 사용했다.
Photo with missing pixels→inpainted photo
[14]의 14900개의 훈련 이미지를 25 에포크동안 배치 크기 4로 훈련시켰고, [43]의 분할을 따르는 100의 홀드-아웃 이미지를 사용하여 테스트했다.
6.3. Errata
이 논문에서 배치 크기 1로 기록된 모든 실험은 bottleneck 레이어의 활성화 함수들이 배치 정규화 연산에서 0으로 처리되며, 사실상 가장 내부의 레이어를 건너뛰게 한다. 이 문제는 공개된 코드에서 처리되었듯이 이 레이어에서 배치 정규화를 제거함으로 고칠 수 있다. 우리는 이러한 변경에 대해 거의 차이가 없음을 관찰했기 때문에 실험을 논문에 있는 그대로 두겠다.