Kaggle: I’m Something of a Painter Myself
더 늦으면 이 후기 안 쓸 거 같아서 새벽에 두서 없이 적었다.
0. (1115) 앞으로의 스터디 방향성
가짜연구소와 반 고흐 전시전
7월 중순부터 나는 가짜연구소라는 커뮤니티에서 진행하는 스터디에 참여했다. 머신러닝 연구 중심 커뮤니티인데 처음 이 커뮤니티를 알게되고 스터디에 참여하려 하니 참 매력적인 스터디 주제가 많았었다. XAI, NLP, GraphML 등등.. 나는 아직 익숙치 않은 (군침도는) 주제의 스터디들이 있었다.

???: 한국인이라면 KoNLP 합시다!
나는 그 중에서 GAN 스터디(반 고흐 전시전 : 2021년 한국의 기록)에 참가했다.
논문 스터디가 끝나고
여름과 가을 동안의 GAN 논문 스터디가 마무리되어가고, 앞으로 이 모임에서 어떤 활동을 진행할지를 의논했다. 이 스터디의 주제가 “반 고흐 전시전”이었던 만큼, 어떠한 화풍을 구현해내는 활동을 찾아본 듯하다. 나왔던 주제는 크게 다음 두 가지였다.
- 인공지능과 예술 공모전 (https://www.aixart.co.kr/html/contest/contest.html)
- I’m Something of a Painter Myself (https://www.kaggle.com/c/gan-getting-started)
투표 결과 Kaggle의 공모전을 나가는 방향이 채택되었다. 우리가 회의할 당시에는 이미 종료된 공모전이지만 GAN을 통해 Monet의 화풍을 구현해보고 Public Leaderboard에서 순위권에 들어보는 것을 나름의 목표로 삼았다. 회의를 통해 두 개의 소그룹으로 나뉘었고, 나는 1조에서 활동하게 되었다.
1. (1122, 1주차) 소그룹 방향 설정
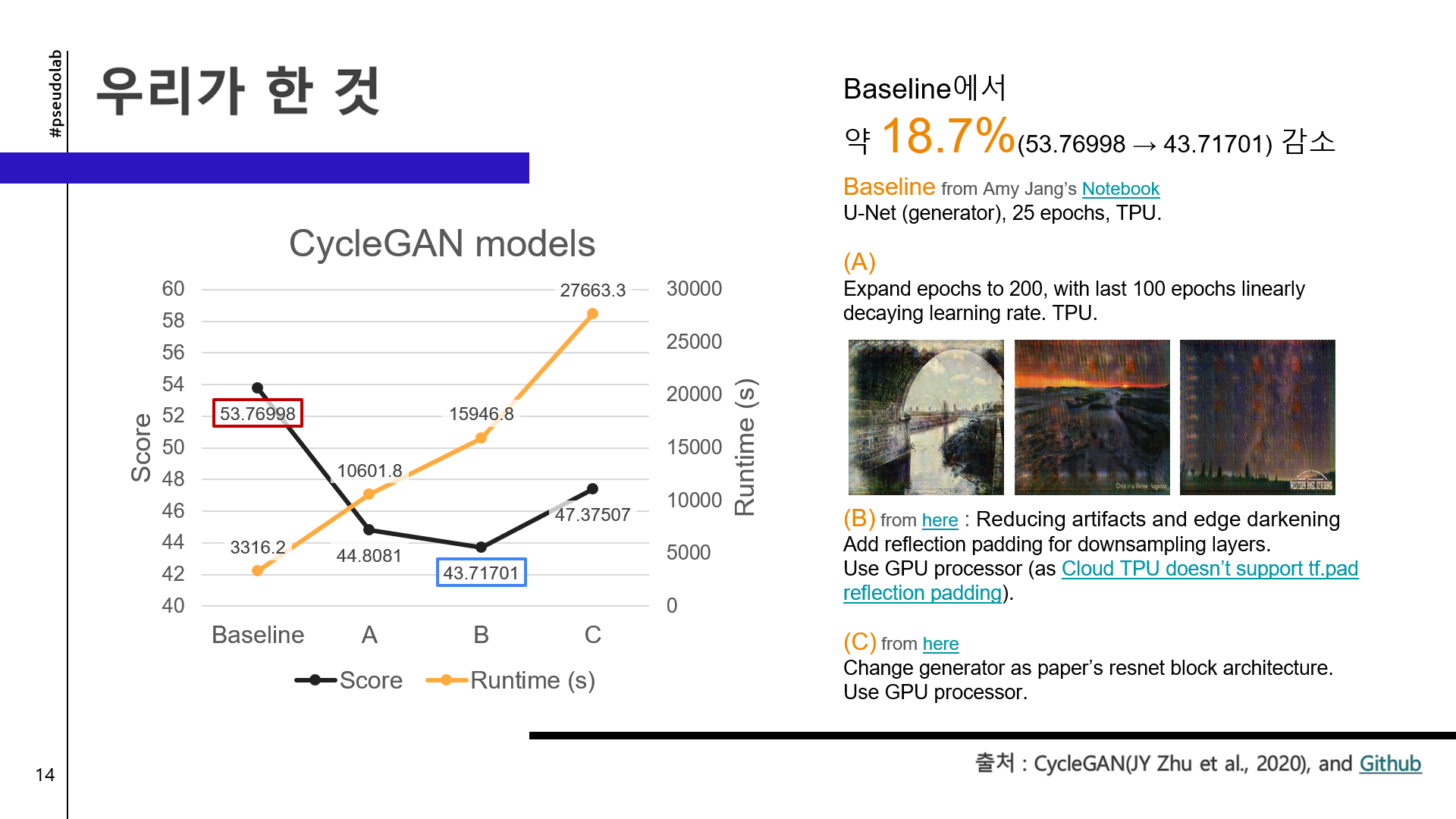
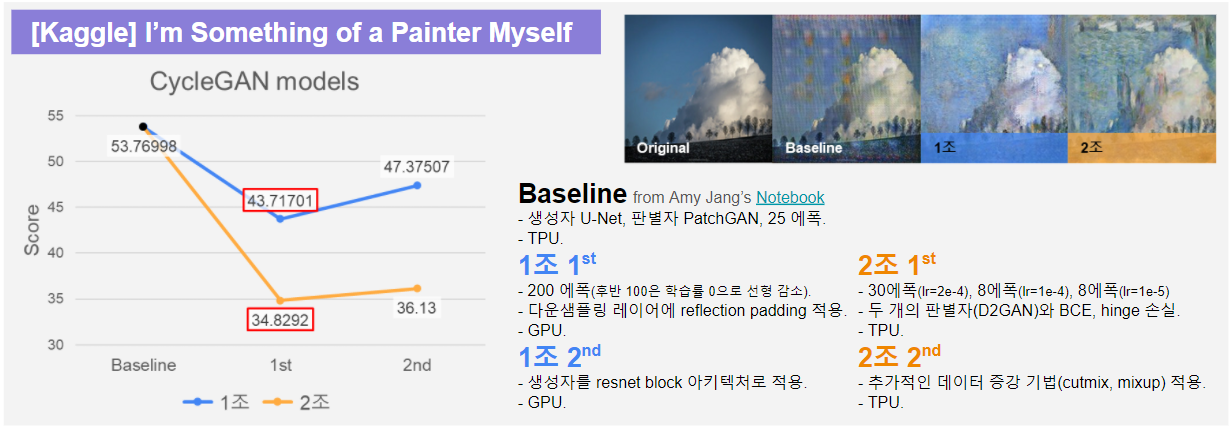
첫 모임에서는 소그룹 1조의 개발 방향을 잡았다. 다음 회의까지 약 일주일 동안 팀원 각자 Kaggle에 공유되어 있는 모델을 baseline 삼아, 각자 score를 높여보기로 했다. 다음 회의 전에 각자의 코드와 score도 공유하기로 했다. Baseline은 Keras를 사용한 Amy Jang의 Monet CycleGAN Tutorial을 채택했다.

나는 당장 떠오르는 아이디어는 없어서, 논문을 최대한 따라가보려고 했다. Amy Jang의 코드는 코드 실습을 충분히 하지 않았던 상황에서 아키텍처 구성을 이해하기 좋았다. 다만, tutorial이라 논문의 스펙을 완전히 따라가지 않은 듯하다. 따라서 일단 코드를 돌려보고 남은 시간에 할 수 있는 내용을 수정해보았다.
Decaying learning rate
전체 모델을 저장하고 불러들이는 방법이 통하지 않아 당시에 난감했었는데, 각 하위 모델(판별자들과 생성자들)의 가중치를 저장하면 된다는 사실을 찾아냈다. (그 때 아직도 생각이 참 좁다는 걸 느꼈다)
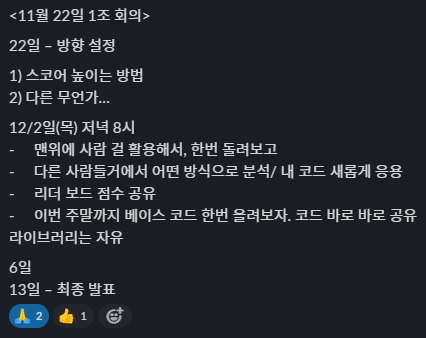
- 30 epochs → 100 epochs → 100 epochs + 100 epochs with linearly decaying LR
- 53.76998 → 44.80810, 10601.8s
Reflection padding
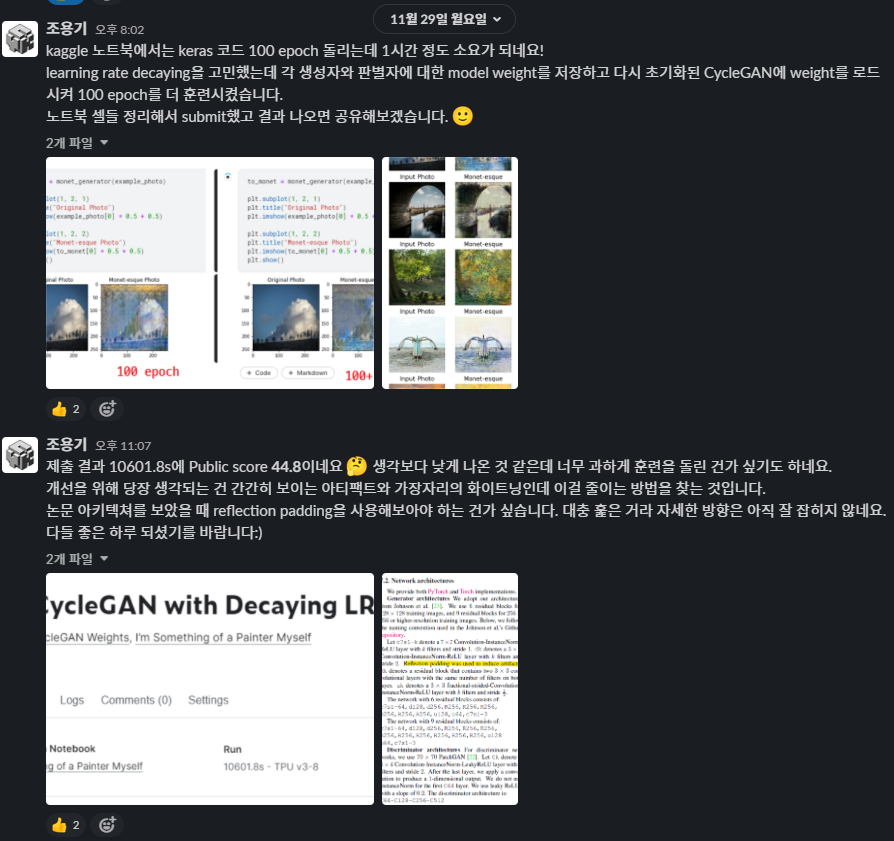
간간히 보이는 아티팩트와 가장자리의 whitening을 (사실 zero padding이면 darkening을 지우는 게 맞을 텐데) 해결하기 위해, 논문에서 사용한 reflection padding을 적용해보았다. 논문이 사용하는 torch와는 다르게 keras에서는 여러 가지 padding 함수를 지원하지 않으며 zero padding만 사용한다. 따라서 이 것도 구글링의 힘을 빌렸다. 다만 TPU 모듈이 tensorflow.pad 함수의 reflection 연산을 지원하지 않아 TPU를 GPU로 돌릴 수 밖에 없었다. 연산을 TPU가 지원하는 함수로 구현하기에는 난이도와 시간이 지원하지 않을 듯했다.
- Change U-Net downsampling padding from zero to reflection (TPU → GPU)
- 44.80810 → 43.71701, 15946.8s
2. (1202, 2주차) 메인 모델 채택 및 개선

내가 개선했던 모델의 Leaderboard 점수가 가장 높아, 1조에서 개선해 볼 모델로 채택되었다. 여기에 팀원들의 의견을 참고해 다같이 모델을 개선하기로 했다. 제안된 의견들은 논문에서 사용한 생성자의 ResNet block 아키텍처를 구현하기, Checkpoint와 EarlyStopping 함수 사용해보기, 그리고 validation 적용해보기 등이었다. 그리고 조금 일찍 모여 다음 전체 회의에서 발표할 내용을 고민해보기로 했다.
Johnson의 CycleGAN을 Keras로!
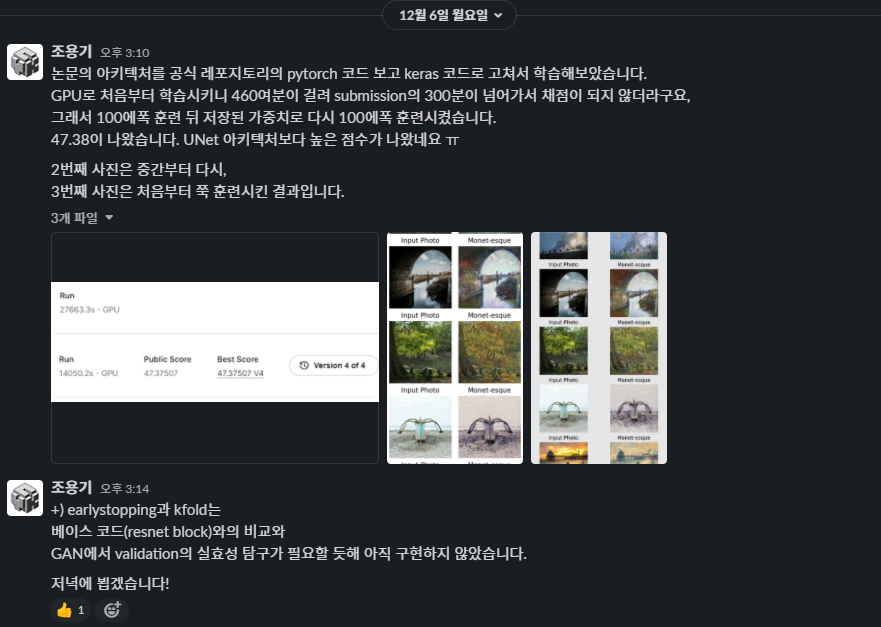
고민하다 논문 저자들이 구현한 pytorch 코드를 내 keras 코드로 옮겨보았다. 두 라이브러리 모두 구현 방식은 간단히 알고 있고 코드 구현 간 유사성이 있어서, 기존의 코드를 수정하는 것은 많이 어렵지는 않았다. 상당히 오래 걸렸다. 늦은 밤까지 코드 옮기고 실행시간이 상당할 것을 예상해서 돌려놓고 잤는데 Kaggle 노트북이 중간에 꺼져서 이게 맞나 싶었다 (^-^,,,) 출근할 때 태블릿 들고 가서 6시간 기다리다 나온 결과를 보니 점수가 없어서 상당히 당혹스러웠다. 알고보니 Kaggle은 submission에서 6시간이 넘어가면 채점을 하지 않아서였다. 그래서 100 에폭 훈련한 가중치를 저장해서 submission 때는 그 가중치를 넘겨 훈련시켰다. 퇴근하기 전까지 너무 피곤했다.
채점된 점수는 오히려 올라갔다… 모델이 너무 한 쪽 모드로 집중해서 훈련이 된 건가 싶다. 아니면 vanishing gradient인가? 당시에는 너무 피곤해서 점수가 안 좋게 나온 이유를 상상하기 힘들었다.
- (Generator) U-Net → Resnet 9 blocks
- 43.71701 → 47.37507, 27663.3s + 14050.2s
다른 개선 사항은 딱히 시도하지 않았다. Early stopping은 GAN이 과적합을 일으키기 힘들며, k-fold validation은 GAN에서 validation/test의 정량화된 방법이 아직 없는 것으로 알고 있어서 그러했다.
전체 회의 발표 준비

우리가 한 걸 공유하자! 라는 생각으로 발표를 준비하기로 했다. 논의 결과 베이스라인 소개, 개선 과정 설명, 고찰로 파트가 나뉘었고 나는 우리가 그 동안 개선해왔던 코드 설명을 작성했다.
4. (1213, 4주차) PseudoCon 준비
전체 회의에서 서로 발표가 끝난 뒤에, 가짜연구회에서 진행하는 PseudoCon을 참가하기로 결정이 되었다. (PseudoCon에서는 스터디나 크루에서의 활동 내용 등을 세션으로 공유한다) Kaggle 참가를 포함하여, 하반기동안 우리 스터디에서 진행했던 내용을 포스터로 만들어 세션에 참가하기로 했다.
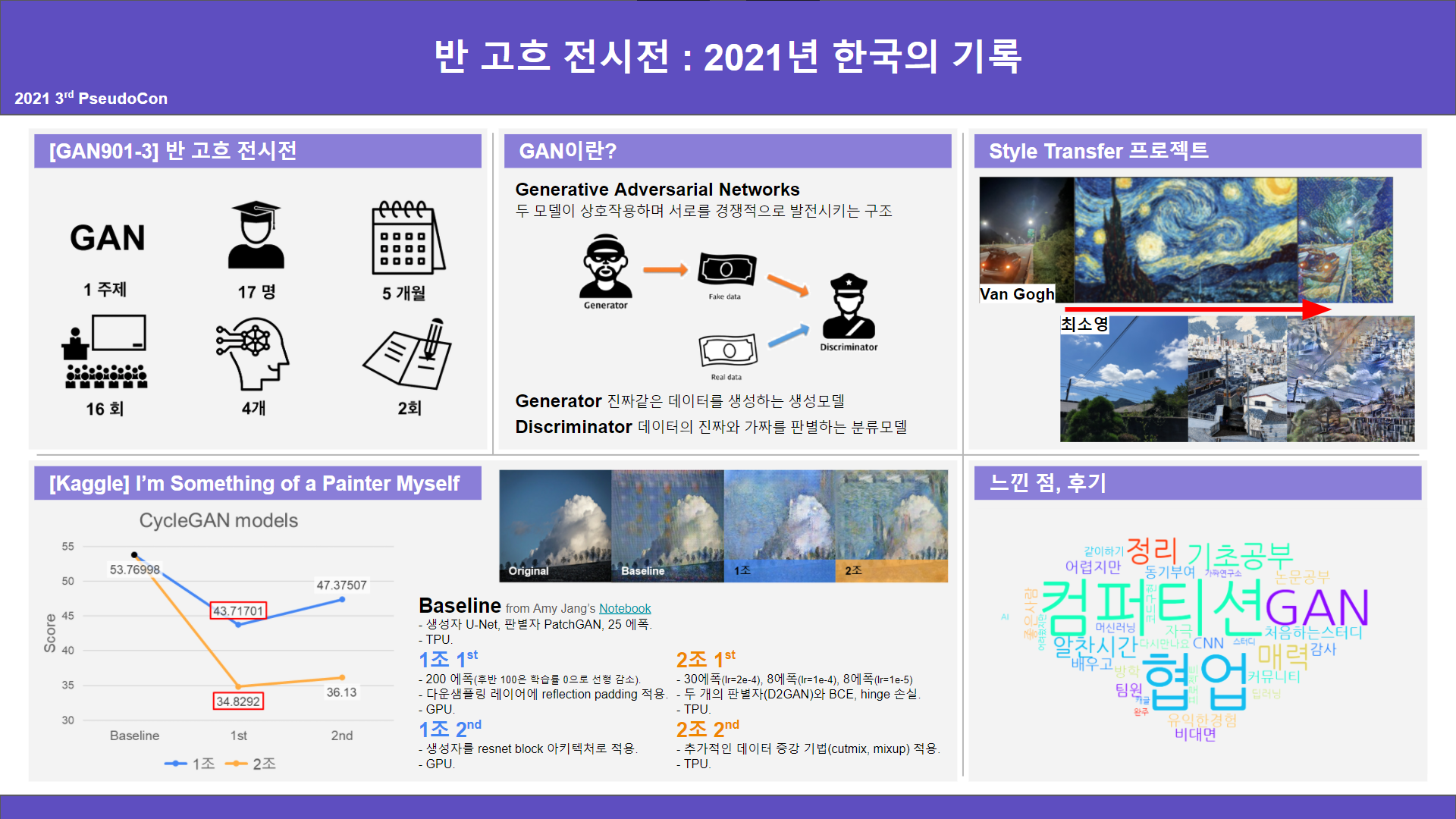
나는 Kaggle에서의 활동 내용을 종합헀다.
5. 후기
써 놓고 보니까 너무 뭐 했는지만 적었네.. PseudoCon때는 야간 근무여서 세션에서 발표를 도울 수 없어 아쉬웠지만, 이러한 활동에 참여하는 것은 흔치 않고 늘 새로운 것 같다. 시간이 된다면 다음 가짜연구소 스터디 그룹이나 Kaggle 크루 등에도 참여하고 싶다. 나름 게을러졌던 한 해의 나 자신에게 가끔씩 채찍을 날려주던 활동이었다. 이러한 스터디를 참여할 기회를 만들어준 커뮤니티와 빌더에게 감사를 드린다.